
Мне всегда было любопытно, почему одни слова запомнить легко, а на другие можно потратить вечность и всё рано продолжать их путать. Особенно остро я столкнулся с такой проблемой, когда начал учить турецкий. Его структурированная и понятная грамматика давалась легко, а вот слова похожи одно на другое и сложно поддавались изучению. Усугубляло и то, что в турецком почти нет англицизмов и интернациональных слов.
Вооружившись этой болью, я решил выяснить — какое же слово является самым сложным. Для этого я воспользовался популярной в последнее время технологией машинного обучения, предварительно собрав для нее список слов, которые я ранее учил.
Нейронные сети
Программа не умеет думать, но может обучаться, подобно человеку.
Нейронная сеть — это математическая модель человеческого мозга. Она состоит из множества нейронов, каждый из которых хранит в себе некоторое значение и связан с одним или несколькими другими нейронами в сети.
Процесс обучения заключается в предоставлении большого количества пар входных и выходных значений. Например, список слов, для каждого из которых заведомо известно — какое из них считается легким, а какое сложным. Модель подгоняет значения своих нейронов так, что бы для входного значения получался заданный результат на выходе.
Результат обучения — это модель, способная предсказывать результат, на основе новых данных. Например, по заданному слову предсказать, будет ли оно сложным или легким. Чем больше примеров будет передано на этапе обучения, тем точнее будут предсказания.
Сбор данных
Итак, нужно подготовить список слов, с разделением на простые и сложные.
Уже несколько месяцев я учу турецкие слова в приложении и у меня накопилась статистика, где для каждого слова я могу посмотреть, как часто я ошибался в процессе работы с ним. Будем считать, что чем больше ошибок я совершал, тем сложнее для меня это слово.
Теперь нужно определиться с тем, что же такое «слово». Нужно представить его в виде чисел, что бы нейронная сеть могла с ним работать. Я выделил следующие показатели, которые могут влиять на оценку сложности:
- Количество символов в слове — это кажется самым очевидным. Чем длиннее слово, тем сложнее его запомнить.
- Тоненькие символы (ı, l, i, j) — это мой личный пунктик. Когда такие символы выстраиваются в ряд, то я вообще не могу их различить.
- Визуально сложные символы (ü, ğ, ş, ç, ö, ı) — не уверен, легче или сложнее учить слова с такими символами, пусть нейросеть сама разбирается с этим
- Необычно произносимые символы (ü, ö, ğ, ş, ç, c) — лишь незначительно отличается от предыдущего пункта
- Количество слогов — этот параметр тесно связан с длиной слова, но всё таки эта характеристика может варьироваться даже для слов с одинаковой длиной
- Попадание слова в топ 10000 самых часто используемых слов — показалось логичным, что если слово часто встречается в любых текстах, то оно уже примелькалось и его будет легче учить
Список самых часто используемых турецких слов я взял здесь.
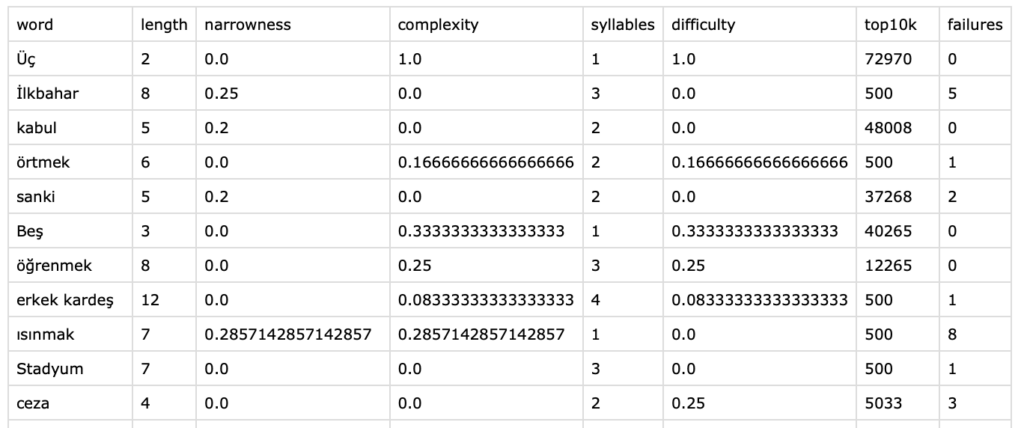
На скриншоте несколько слов из выборки для обучения. Последний столбец показывает, как часто я ошибался в этом слове во время обучения. Цель — научиться предсказывать эту величину.
Обучение модели
Когда данные подготовлены, можно приступать к обучению. Я выбрал CreateML — простой в использовании инструмент от компании Apple. Нужно просто загрузить в него подготовленную таблицу с данными, выбрать целевое поле (в нашем случае, поле failures), указать поля с параметрами, запустить обучение.
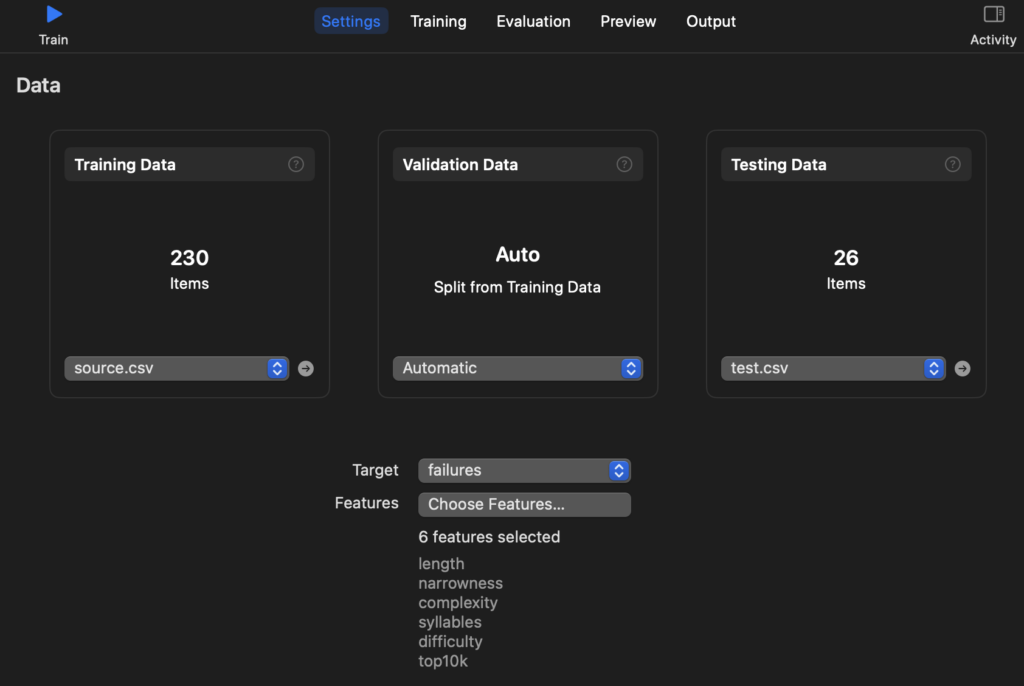
Результат обучения — готовая модель, которая может предсказывать сложность слова, по его параметрам.
Поиск самого сложного слова
Имея обученную модель, я решил взять выгрузку из 10 тысяч самых популярных турецких слов и найти среди них самое сложное.
Так, самым сложным оказалось слово söyleyebileceğim с рейтингом сложности 4.1951 (по мнению нейронной сети, именно столько раз я ошибусь в процессе изучения этого слова). То, что это слово сложное — я согласен. Мне его даже произнести трудно.
Просматривая выгрузку с рейтингом сложности, обратил внимание еще на пару интересных слов:
yapabileceğimi с рейтингом 3.5782
yapabileceğini с рейтингом 3.5780
У этих двух слов рейтинг выглядит очень похожим. Да и на вид оба эти слова почти не отличаются. Так что и здесь результат похож на правду.
Самое легкое слово
Любопытный результат оказался при поиске самого легкого слова.
Им оказалось слово bu с рейтингом -0.2390
Не знаю, почему число отрицательное. Быть может, нейросеть посчитала, что я это слово знал еще до начала обучения )) Но в целом я и тут согласен — специально это слово я никогда не учил, оно настолько частое, что было изучено мной естественным путем.
Заключение
Обученная модель данных действительно дает правдоподобный результат. Есть некоторые сомнения относительно точности предсказаний. Но в качестве развлекательной цели, результат меня точно устроил.
Примечательно, что модель обучена исключительно на моем личном опыте. То есть, я получил оценку сложности турецких слов, подходящую именно мне.
В будущем, можно улучшить модель данных и подумать над тем, что бы внедрить ее в приложение. Например, пользователю будут даваться не просто случайные подборки слов, а подбираться персонализированные наборы к обучению.
Другая интересная идея — научить модель предсказывать оптимальные интервалы для повторения слов на основе их сложности и интенсивности обучения пользователя